How we built Norway's best open-source AI
m51Lab-NorskMistral-119B outperforms all published models on 7 out of 8 tasks in NorEval.
The goal was simple: build the best open-source Norwegian language model. Not with a team of 20 researchers and 256 GPUs over 8 days, as UiO did with NorMistral. But with cloud-based GPU power, open datasets, and a pragmatic approach to fine-tuning.
The result was m51Lab-NorskMistral-119B. A fine-tuned version of Mistral Small 4 that outperforms all published models on 7 out of 8 core tasks in the NorEval benchmark.
What is NorEval?
NorEval is the Norwegian standard for evaluating language models, developed by the University of Oslo and published at ACL 2025. The benchmark covers 24 datasets across 9 categories, ranging from commonsense reasoning and factual knowledge to truthfulness and reading comprehension. It tests both Bokmål and Nynorsk, making it particularly demanding for models trained primarily on English.
The reigning champion was NorMistral-11B-thinking from UiO, built with 250 billion tokens of Norwegian text and trained on 256 GPUs over 8.5 days. An impressive project, but not one a small team can replicate.
We wanted to show that there is another way.
Our approach: Smart over large
Instead of training a model from scratch, we chose Mistral Small 4 as our starting point. A 119B parameter Mixture-of-Experts model (MoE) with an Apache 2.0 license. The MoE architecture means only ~6 billion parameters are active per token, so inference is surprisingly efficient despite the large total size.
Mistral Small 4 had already seen Norwegian text during its original training. Our job was to unlock that potential.
Three phases
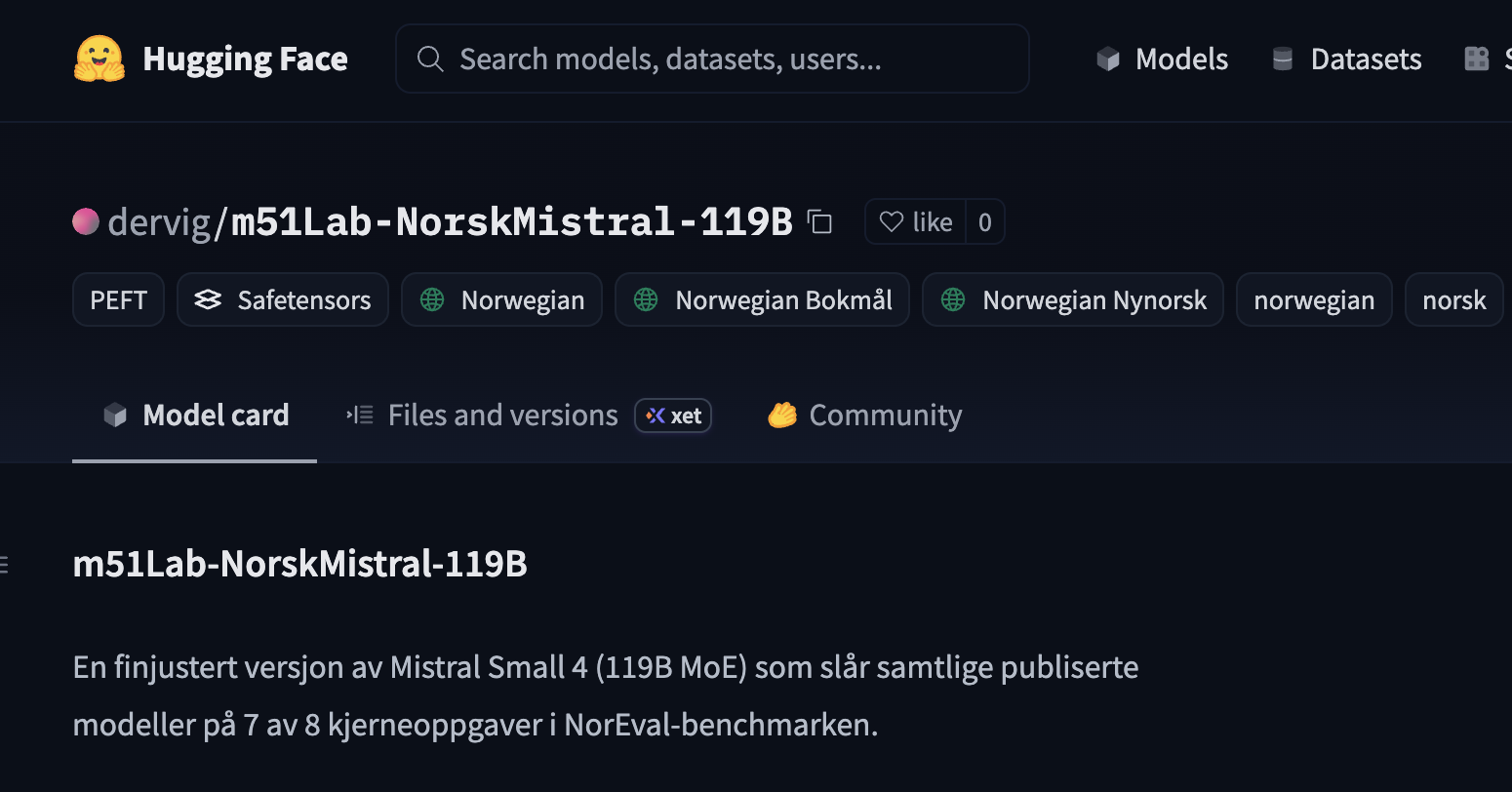
Phase 1, Methodology: Getting the evaluation methodology right alone yielded enormous gains. We tested 5 different prompt variants per task (best-of-5), used 16-shot examples where the NorEval protocol allows it, and ensured correct chat-template usage. The result: average score jumped from 43% to 75%. An increase of over 30 percentage points, without training anything at all.
Phase 2, Fine-tuning: We trained the model with LoRA (Low-Rank Adaptation) on a curated dataset of 13,375 Norwegian examples. The dataset was assembled from NbAiLab (Norwegian alpaca, Nynorsk translations, factual knowledge), synthetic data we generated ourselves, and English anti-forgetting examples. Everything was checked against the NorEval test set to avoid contamination.
Phase 3, Evaluation: Full evaluation on the entire test set. No subsampling, no shortcuts. Both the trained model and the base model were tested to isolate the effect of the training.
Results
Here is the final comparison against the best published models in NorEval:
| Task | m51-NorskMistral | Best published | Margin |
|---|---|---|---|
| Commonsense reasoning (BM) | 75.7% | 72.2% | +3.5pp |
| Commonsense reasoning (NN) | 63.2% | 52.6% | +10.6pp |
| Open-book QA (BM) | 95.7% | 87.4% | +8.3pp |
| Open-book QA (NN) | 93.3% | 88.9% | +4.4pp |
| Truthfulness (BM) | 77.9% | 74.6% | +3.3pp |
| Truthfulness (NN) | 82.5% | 73.7% | +8.8pp |
| Norwegian knowledge, NRK Quiz (BM) | 66.5% | 63.7% | +2.8pp |
| Norwegian knowledge, NRK Quiz (NN) | 65.1% | 71.9% | -6.8pp |
| Average | 76.8% | 73.1% | +3.7pp |
m51-NorskMistral is best on 7 out of 8 tasks. The only exception is the NRK Quiz in Nynorsk, where NorMistral-11B has an advantage thanks to its 250 billion tokens of Norwegian text, including far more Nynorsk than our model has seen.
Fine-tuning delivered where it counted
Fine-tuning with LoRA produced measurable improvements, especially on the Bokmål tasks:
| Task | Before training | After training | Gain |
|---|---|---|---|
| Commonsense BM | 71.7% | 75.7% | +4.0pp |
| NRK Quiz BM | 64.3% | 66.5% | +2.2pp |
| Truthfulness BM | 77.1% | 77.9% | +0.8pp |
| NRK Quiz NN | 63.6% | 65.1% | +1.5pp |
We used conservative hyperparameters (LoRA rank 32, learning rate 5e-5) to prevent the model from losing what it already knew. The strategy worked: no dramatic regression on any task.
Hardware: 7 x NVIDIA H100 in the cloud
Fine-tuning a model with 119 billion parameters is demanding. The model weighs 238 GB in BF16 precision — more than even the most powerful single GPUs can accommodate.
We ran 7 NVIDIA H100 80 GB GPUs in parallel via RunPod, using FSDP2 (Fully Sharded Data Parallel) to distribute the model across GPUs. Each GPU received ~34 GB of model weights, with ~29 GB of headroom for activations and gradients.
To put it in perspective: an equivalent on-premises machine with 7x H100, NVLink interconnect, and 1.5 TB RAM would cost around 2.5 million NOK. Cloud-based GPU power makes this type of project possible without tying up capital in hardware.
Training setup in detail
Modell: Mistral Small 4 119B MoE (128 eksperter, 4 aktive) Presisjon: BF16 (bfloat16) Adapter: LoRA r=32, alpha=64 Hardware: 7x NVIDIA H100 80GB SXM Parallellisering: FSDP2 (layer-wrap på Mistral4DecoderLayer) Treningsdata: 13.375 eksempler (norsk + engelsk anti-forgetting) Epoker: 2 Treningstid: 3 timer Sekvenslengde: 1024 tokens
The road here: Bugs, OOM, and three pod iterations
It did not go smoothly. We went through three GPU configurations before training worked:
- 4x H100: Out of memory. 119B in BF16 requires more than 320 GB of GPU memory.
- 6x H100: Almost enough, but OOM during the backward pass (74 GB/GPU, needed 4 GB more).
- 7x H100: Perfect. 51 GB/GPU with 29 GB headroom. Stable throughout the entire training run.
Along the way we discovered a critical bug in bitsandbytes (the popular quantization library) that completely blocked QLoRA on MoE architectures. The solution was to drop quantization and run full BF16 LoRA with FSDP2. More expensive in GPU memory, but superior in quality.
The first evaluation appeared to produce terrible results: 21% accuracy, below random guessing. The cause? Model weights were silently ignored during loading, and the model was responding with random values. That kind of silent failure is a real risk when working with new model architectures.
Contamination check: No cheating
We ran a contamination check of the training data against all NorEval test sets. Only 10 out of 13,385 examples (0.07%) had substring matches, mainly short proper-noun overlaps. These were removed as a precaution, and all are documented for full transparency.
We also checked whether the high Open-book QA results (95.7%) could be attributed to data leakage in the few-shot examples. A control run with 0-shot gave 88%, still well above all other models.
What we learned
1. Methodology trumps training. The biggest improvement came from evaluating the model correctly, not from fine-tuning. Multi-prompt evaluation (5 different phrasings per task) showed that a single prompt variant systematically underestimates what the model is capable of. This insight is equally relevant for organizations deploying AI in production.
2. Large models know more than they show. Mistral Small 4 already "knew" Norwegian. LoRA fine-tuning on 13,000 examples was enough to surface and amplify that capacity. You do not always need to train from scratch.
3. Full evaluation is non-negotiable. Subsample evaluation (150 out of 3,600 examples) produced misleading numbers. Without full evaluation we would have published incorrect results. Rigorous testing is just as important as the training itself.
4. MoE delivers a lot of model for the money. 119 billion parameters sounds massive, but with only 6 billion active per token, inference is comparable to a 7B model. The capacity of a large model, the efficiency of a small one.
Try the model yourself
Try m51Lab-NorskMistral-119B directly here. The model runs on an NVIDIA A100 80 GB GPU via RunPod Serverless.
m51-NorskMistral-119B is open source under Apache 2.0. Download the LoRA adapter and use it with Mistral Small 4 as the base.
Download the model from HuggingFace
Important: The LoRA adapter on HuggingFace is quantized to Q4_K_M and requires approximately 70 GB of GPU memory. A single A100 80 GB or H100 80 GB is sufficient. The model cannot be run on a regular laptop. Use a cloud-based GPU service such as RunPod, Lambda Labs, or similar.
All scripts, configurations, and training data will be made available so that the results can be reproduced.
About m51
m51.ai builds AI solutions for Norwegian businesses. m51-NorskMistral demonstrates what a small, focused team can achieve with the right approach and modern tooling.
The same AI expertise powers m51.ai, the platform where marketing teams and agencies use specialized AI agents to streamline everything from content strategy and SEO to advertising and reporting.
Have an AI project you would like to discuss? Get in touch at [email protected].
Technical details and the complete build log are available in the project's GitHub repository.
After NorskMistral we built NorskGemma4-31B, a model that scores even higher on NorEval with a fraction of the parameters.
Read next: Smaller model, better results. NorskGemma4-31B
Related research: We pruned MiniMax-M2.7, the first public REAP variant