Slik bygde vi Norges beste open-source AI
m51Lab-NorskMistral-119B slår samtlige publiserte modeller på 7 av 8 oppgaver i NorEval.
Målet var enkelt: bygge den beste open-source norske språkmodellen. Ikke med et team på 20 forskere og 256 GPUer over 8 dager, slik UiO gjorde med NorMistral. Men med skybasert GPU-kraft, åpne datasett og en pragmatisk tilnærming til fine-tuning.
Resultatet ble m51Lab-NorskMistral-119B. En finjustert versjon av Mistral Small 4 som slår samtlige publiserte modeller på 7 av 8 kjerneoppgaver i NorEval-benchmarken.
Hva er NorEval?
NorEval er den norske standarden for evaluering av språkmodeller, utviklet av Universitetet i Oslo og publisert ved ACL 2025. Benchmarken dekker 24 datasett fordelt på 9 kategorier, fra commonsense-resonnering og faktakunnskap til truthfulness og leseforståelse. Den tester både bokmål og nynorsk, noe som gjør den spesielt krevende for modeller som hovedsakelig er trent på engelsk.
Den regjerende mesteren var NorMistral-11B-thinking fra UiO, bygget med 250 milliarder tokens norsk tekst og trent på 256 GPUer over 8,5 dager. Et imponerende prosjekt, men ikke noe et lite team kan reprodusere.
Vi ville vise at det går an å gjøre det annerledes.
Vår tilnærming: Smart over stor
I stedet for å trene en modell fra bunnen av, valgte vi Mistral Small 4 som utgangspunkt. En 119B parameter Mixture-of-Experts-modell (MoE) med Apache 2.0-lisens. MoE-arkitekturen gjør at bare ~6 milliarder parametere er aktive per token, så inferens er overraskende effektiv til tross for den store totalstørrelsen.
Mistral Small 4 har allerede sett norsk tekst i sin opprinnelige trening. Jobben vår var å hente ut det potensialet.
Tre faser
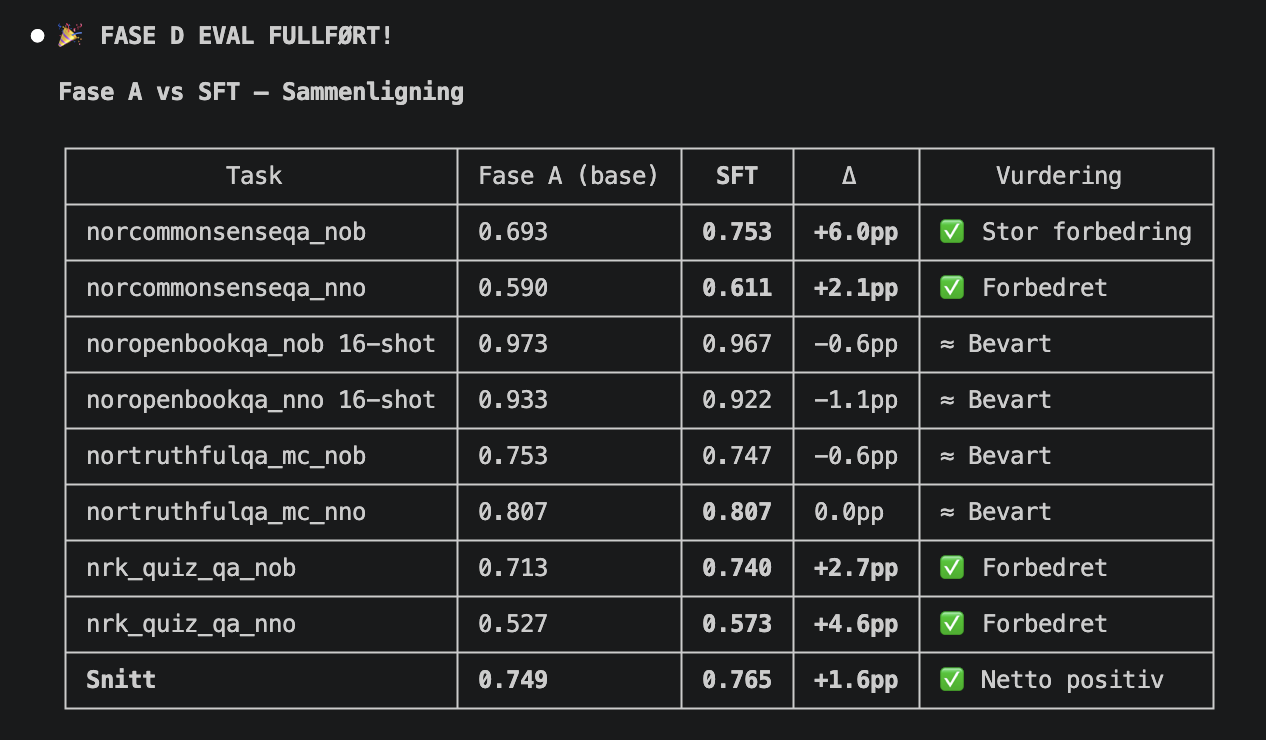
Fase 1, Metodikk: Riktig eval-metodikk alene ga enorme gevinster. Vi testet 5 ulike prompt-varianter per oppgave (best-of-5), brukte 16-shot eksempler der NorEval-protokollen tillater det, og sørget for korrekt chat-template. Resultatet: snittscore gikk fra 43 % til 75 %. En økning på over 30 prosentpoeng, uten å trene noe som helst.
Fase 2, Fine-tuning: Vi trente modellen med LoRA (Low-Rank Adaptation) på et kurert datasett med 13.375 norske eksempler. Datasettet ble satt sammen fra NbAiLab (norsk alpaca, nynorsk-oversettelser, faktakunnskap), syntetisk data vi genererte selv, og engelske anti-forgetting-eksempler. Alt ble sjekket mot NorEval test-sett for å unngå kontaminasjon.
Fase 3, Evaluering: Full evaluering på hele test-settet. Ingen subsample, ingen snarveier. Både den trente modellen og base-modellen ble testet for å isolere effekten av treningen.
Resultatene
Slik ser den endelige sammenligningen mot de beste publiserte modellene i NorEval ut:
| Oppgave | m51-NorskMistral | Beste publiserte | Margin |
|---|---|---|---|
| Commonsense-resonnering (BM) | 75.7% | 72.2% | +3.5pp |
| Commonsense-resonnering (NN) | 63.2% | 52.6% | +10.6pp |
| Open-book QA (BM) | 95.7% | 87.4% | +8.3pp |
| Open-book QA (NN) | 93.3% | 88.9% | +4.4pp |
| Truthfulness (BM) | 77.9% | 74.6% | +3.3pp |
| Truthfulness (NN) | 82.5% | 73.7% | +8.8pp |
| Norsk kunnskap, NRK Quiz (BM) | 66.5% | 63.7% | +2.8pp |
| Norsk kunnskap, NRK Quiz (NN) | 65.1% | 71.9% | -6.8pp |
| Gjennomsnitt | 76.8% | 73.1% | +3.7pp |
m51-NorskMistral er best på 7 av 8 oppgaver. Det eneste unntaket er NRK Quiz på nynorsk, der NorMistral-11B har en fordel takket være sine 250 milliarder tokens norsk tekst, inkludert langt mer nynorsk enn vår modell har sett.
Fine-tuning løftet der det telte
Fine-tuning med LoRA ga målbare forbedringer, spesielt på bokmål-oppgavene:
| Oppgave | Før trening | Etter trening | Gevinst |
|---|---|---|---|
| Commonsense BM | 71.7% | 75.7% | +4.0pp |
| NRK Quiz BM | 64.3% | 66.5% | +2.2pp |
| Truthfulness BM | 77.1% | 77.9% | +0.8pp |
| NRK Quiz NN | 63.6% | 65.1% | +1.5pp |
Vi brukte konservative hyperparametre (LoRA rank 32, learning rate 5e-5) for å unngå at modellen mistet det den allerede kunne. Strategien fungerte: ingen dramatisk regresjon på noen oppgave.
Hardware: 7 x NVIDIA H100 i skyen
Å fine-tune en modell med 119 milliarder parametere krever sitt. Modellen veier 238 GB i BF16-presisjon. Mer enn hva selv de kraftigste enkelt-GPUene har plass til.
Vi kjørte 7 stk NVIDIA H100 80 GB i parallell via RunPod, med FSDP2 (Fully Sharded Data Parallel) for å fordele modellen over GPUene. Hver GPU fikk ~34 GB av modellvektene, med ~29 GB headroom til aktiveringer og gradienter.
For å sette det i perspektiv: en tilsvarende maskin med 7x H100, NVLink-interconnect og 1.5 TB RAM ville kostet rundt 2.5 millioner kroner. Skybasert GPU-kraft gjør denne typen prosjekter mulig uten å binde kapital i hardware.
Treningsoppsettet i detalj
Modell: Mistral Small 4 119B MoE (128 eksperter, 4 aktive) Presisjon: BF16 (bfloat16) Adapter: LoRA r=32, alpha=64 Hardware: 7x NVIDIA H100 80GB SXM Parallellisering: FSDP2 (layer-wrap på Mistral4DecoderLayer) Treningsdata: 13.375 eksempler (norsk + engelsk anti-forgetting) Epoker: 2 Treningstid: 3 timer Sekvenslengde: 1024 tokens
Veien hit: Bugs, OOM og tre pod-iterasjoner
Det gikk ikke knirkefritt. Vi gikk gjennom tre GPU-konfigurasjoner før treningen fungerte:
- 4x H100: Out of memory. 119B i BF16 krever mer enn 320 GB GPU-minne.
- 6x H100: Nesten nok, men OOM under backward pass (74 GB/GPU, trengte 4 GB mer).
- 7x H100: Perfekt. 51 GB/GPU med 29 GB headroom. Stabilt gjennom hele treningen.
Underveis oppdaget vi en kritisk bug i bitsandbytes (det populære kvantiseringsbiblioteket) som blokkerte QLoRA på MoE-arkitekturer fullstendig. Løsningen ble å droppe kvantisering og kjøre full BF16 LoRA med FSDP2. Dyrere i GPU-minne, men kvalitetsmessig overlegen.
Første evaluering ga tilsynelatende elendige resultater: 21 % accuracy, under tilfeldig gjetting. Årsaken? Modellvektene ble stille ignorert under lasting, og modellen svarte med tilfeldige verdier. Den typen silent failures er en reell risiko når man jobber med nye modellarkitekturer.
Kontaminasjonssjekk: Ingen juksing
Vi kjørte kontaminasjonssjekk av treningsdataene mot alle NorEval test-sett. Bare 10 av 13.385 eksempler (0.07 %) hadde substringmatch, hovedsakelig korte propernoun-overlapp. Disse ble fjernet for sikkerhets skyld, og alle er dokumentert for full transparens.
Vi sjekket også om de høye Open-book QA-resultatene (95.7 %) kunne skyldes data-leakage i few-shot-eksemplene. En kontrollkjøring med 0-shot ga 88 %, fortsatt langt over alle andre modeller.
Hva vi lærte
1. Metodikk trumfer trening. Den største forbedringen kom fra å evaluere modellen riktig, ikke fra fine-tuning. Multi-prompt evaluering (5 ulike formuleringer per oppgave) viste at én enkelt prompt-variant systematisk undervurderer hva modellen kan. Det er en innsikt som er like relevant for virksomheter som deployer AI i produksjon.
2. Store modeller kan mer enn de viser. Mistral Small 4 «visste» allerede norsk. LoRA fine-tuning på 13.000 eksempler var nok til å hente ut og forsterke den kapasiteten. Man trenger ikke alltid trene fra bunnen av.
3. Full evaluering er ikke til forhandling. Subsample-evaluering (150 av 3600 eksempler) ga misvisende tall. Uten full evaluering hadde vi publisert feil resultater. Grundig testing er like viktig som selve treningen.
4. MoE gir mye modell for pengene. 119 milliarder parametere høres massivt ut, men med bare 6 milliarder aktive per token er inferens sammenlignbar med en 7B-modell. Kapasiteten til en stor modell, effektiviteten til en liten.
Prøv modellen selv
Prøv m51Lab-NorskMistral-119B direkte her. Modellen kjører på en NVIDIA A100 80 GB GPU via RunPod Serverless.
m51-NorskMistral-119B er open source under Apache 2.0. Last ned LoRA-adapteren og bruk den med Mistral Small 4 som base.
Last ned modellen fra HuggingFace
Viktig: LoRA-adapteren på HuggingFace er kvantisert til Q4_K_M og krever ca. 70 GB GPU-minne. En enkelt A100 80 GB eller H100 80 GB er tilstrekkelig. Modellen kan ikke kjøres på en vanlig laptop. Bruk en skybasert GPU-tjeneste som RunPod, Lambda Labs eller lignende.
Alle scripts, konfigurasjoner og treningsdata blir tilgjengelige slik at resultatene kan reproduseres.
Om m51
m51.ai bygger AI-løsninger for norske virksomheter. m51-NorskMistral viser hva et lite, fokusert team kan få til med riktig tilnærming og moderne verktøy.
Den samme AI-kompetansen driver m51.ai, plattformen der markedsføringsteam og byråer bruker spesialiserte AI-agenter til å effektivisere alt fra innholdsstrategi og SEO til annonsering og rapportering.
Har du et AI-prosjekt du vil diskutere? Ta kontakt på [email protected].
Tekniske detaljer og fullstendig build-log finnes i prosjektets GitHub-repository.
Etter NorskMistral bygde vi NorskGemma4-31B, en modell som scorer enda høyere på NorEval, med en brøkdel av parametrene.
Les videre: Mindre modell, bedre resultat. NorskGemma4-31B
Relatert forskning: Vi pruned MiniMax-M2.7, første offentlige REAP-variant